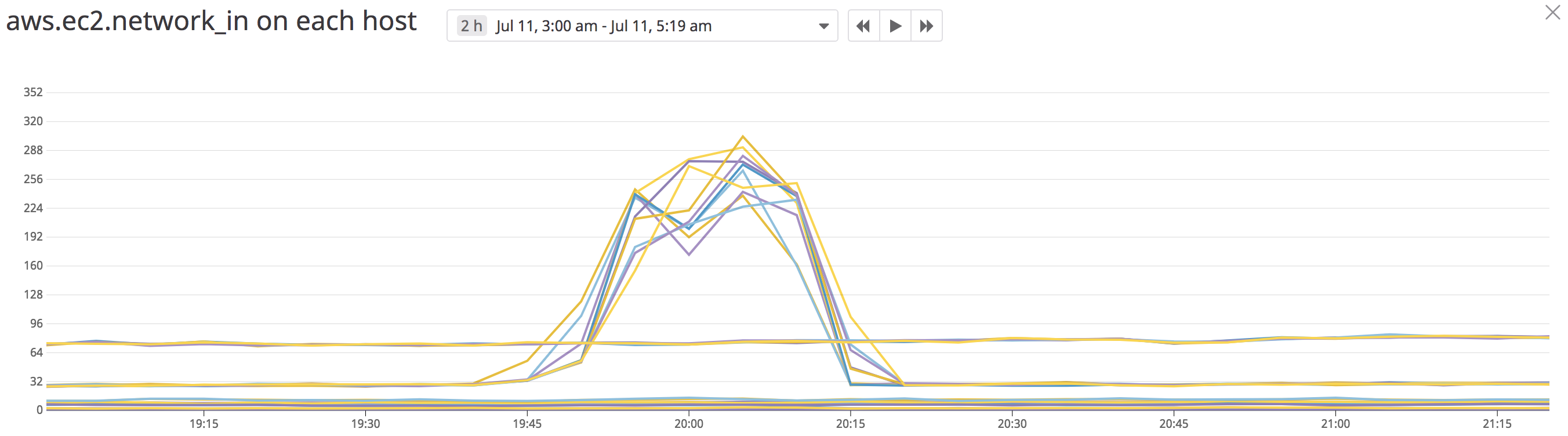
At Tubi, we actively involved in Service Mesh to make our service elastic and robust, our internal backend services already use NGINX, Envoy and Consul for more than an year. Couple of weeks ago, when we decided move our frontend user facing service to Consul, we observe 10 times traffic spike and it bring frontend service down.
The stacktrace indicate application can’t resolve DNS
Error: getaddrinfo EAI_AGAIN xxx.service.tubi:8080
at Object._errnoException (util.js:1024:11)
at errnoException (dns.js:55:15)
at GetAddrInfoReqWrap.onlookup [as oncomplete] (dns.js:92:26)
Before move frontend service to Consul, frontend service request internal service by NGINX with static domain name. with Consul, frontend request internal service with IP and port by Consul.
What cause 10x traffic spike?
I started by using iftop to identify which host cause increased traffic, it turned out to be Consul server.
I was able to see what traffic is sent and received from Consul server with tcpdump,
$ tcpdump -A -s 10240 host 172.40.29.19
Request
14:07:32.078034 IP ip-172-40-24-253.us-west-2.compute.internal.53681 > ip-172-40-29-19.us-west-2.compute.internal.8300: Flags [P.], seq 1918:2213, ack 20044, win 1620, options [n
op,nop,TS val 112366405 ecr 1925348389], length 295
Health.ServiceNodes..AllowStale..Connect..Datacenter.us-west-2-production.MaxQueryTime..MaxStaleDuration..MinQueryIndex..NodeMetaFilters..Require
Consistent..ServiceAddress..ServiceName.xxx.ServiceTag..Source..Datacenter..Ip..Node..Segment..TagFilter..Token.
14:07:32.078087 IP ip-172-40-29-19.us-west-2.compute.internal.8300 > ip-172-40-24-253.us-west-2.compute.internal.53681: Flags [.], ack 2213, win 1531, options [nop,nop,TS val 192
5348422 ecr 112366405], length 0
Response
14:07:32.078317 IP ip-172-40-29-19.us-west-2.compute.internal.8300 > ip-172-40-24-253.us-west-2.compute.internal.53681: Flags [P.], seq 20056:24152, ack 2213, win 1531, options [
nop,nop,TS val 1925348422 ecr 112366405], length 4096
Error..Seq..%0..ServiceMethod.Health.ServiceNodes..ConsistencyLevel..Index...6F.KnownLeader..LastContact..Nodes...Checks...CheckID.serfHealth.CreateIndex..1.>.Definitio
n..DeregisterCriticalServiceAfter..HTTP..Header..Interval..Method..TCP..TLSSkipVerify..Timeout..ModifyIndex..1.>.Name.Serf Health Status.Node.xxx.Notes..Output.Agent a
live and reachable.ServiceID..ServiceName..ServiceTags..Status.passing..CheckID.service:xxx-8000.CreateIndex..1.>.Definition..DeregisterCriticalServiceAfter..HTTP..H
eader..Interval..Method..TCP..TLSSkipVerify..Timeout..ModifyIndex...6F.Name.. Service 'xxx' check.Node.xxx.Notes..Output..BHTTP GET http://localhost:8000/
xxx/health: 200 OK Output: .ServiceID.xxx-8000.ServiceName.xxx.ServiceTags..Status.passing.Node..Address.172.40.36.169.CreateIndex
Looks like Consul agent resolve every DNS by making RPC call to Consul server. I’m not familiar with Consul at that time but it doesn’t make sense as every DNS resolve need an RPC call from Consul agent to server
- It looks slow
- Consul server will be the bottleneck, consider we have dozen of services resolve tens of thousands of DNS every seconds
Add DNS cache for Consul
Consul allow you to configure DNS TTL values with simple config, you also need to setup an local caching name server like Dnsmasq to make TTL actually works.
Without Dnsmasq, we have iptable rules to direct DNS queries to Consul agent listening on 8600
[root@localhost ~]# iptables -t nat -A PREROUTING -p udp -m udp --dport 53 -j REDIRECT --to-ports 8600
[root@localhost ~]# iptables -t nat -A PREROUTING -p tcp -m tcp --dport 53 -j REDIRECT --to-ports 8600
[root@localhost ~]# iptables -t nat -A OUTPUT -d localhost -p udp -m udp --dport 53 -j REDIRECT --to-ports 8600
[root@localhost ~]# iptables -t nat -A OUTPUT -d localhost -p tcp -m tcp --dport 53 -j REDIRECT --to-ports 8600
With Dnsmasq, we remove those iptable rules as Dnsmasq listen on port 53, Dnsmasq forward DNS query to Consul agent.
However, even with Dnsmasq, the number of RPC request still the same.
How DNS resolved?
It looks the DNS cache doesn’t work, but I don’t know which part cause the problem, iptable? Dnsmasq? Consul?
I started by check if iptable rules is being removed.
For service without Dnsmasq,
$ iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
REDIRECT udp -- anywhere anywhere udp dpt:domain redir ports 8600
REDIRECT tcp -- anywhere anywhere tcp dpt:domain redir ports 8600
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
REDIRECT udp -- anywhere localhost udp dpt:domain redir ports 8600
REDIRECT tcp -- anywhere localhost tcp dpt:domain redir ports 8600
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
For service with Dnsmasq,
$ iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
iptable rules is removed, DNS query should go to Dnsmasq instead of Consul, to make sure Dnsmasq get the traffic
$ tcpdump -l -e -n host -i any 127.0.0.1 and port 53
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
14:54:27.892205 In 00:00:00:00:00:00 ethertype IPv4 (0x0800), length 91: 127.0.0.1.43528 > 127.0.0.1.53: 6925+ A? xxx.service.tubi. (47)
14:54:27.892244 In 00:00:00:00:00:00 ethertype IPv4 (0x0800), length 139: 127.0.0.1.53 > 127.0.0.1.43528: 6925 3/0/0 A 172.40.24.89, A 172.40.17.232, A 172.40.45.139 (95)
To make sure Consul get the traffic
$ tcpdump -l -e -n host -i any 127.0.0.1 and port 8600
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
14:55:37.885423 In 00:00:00:00:00:00 ethertype IPv4 (0x0800), length 86: 127.0.0.1.29979 > 127.0.0.1.8600: UDP, length 42
14:55:37.885927 In 00:00:00:00:00:00 ethertype IPv4 (0x0800), length 136: 127.0.0.1.8600 > 127.0.0.1.29979: UDP, length 92
14:55:37.886777 In 00:00:00:00:00:00 ethertype IPv4 (0x0800), length 86: 127.0.0.1.60363 > 127.0.0.1.8600: UDP, length 42
tcpdump don’t decode packet as 8600 is not an standard domain service port, add
-Aoption or use wiredshard to display detailed information.
To make sure Dnsmasq forward DNS query to Consul, I use strace to monitor network system calls,
$ strace -p $DNSMASQ_PID -f -e trace=network -s 10000 2>&1 | grep 'sin_addr=inet_addr("127.0.0.1")'
sendto(12, "\263\177\1\0\0\1\0\0\0\0\0\0\20xxx\7service\4tubi\0\0\34\0\1", 47, 0, {sa_family=AF_INET, sin_port=htons(8600), sin_addr=inet_addr("127.0.0.1")}, 16) = $
7
recvfrom(12, "\263\177\205\200\0\1\0\0\0\1\0\f\20xxx\7service\4tubi\0\0\34\0\1\300%\0\6\0\1\0\0\0\0\0&\2ns\300%\nhostmaster\300%[\374\357\331\0\0\16\20\0\0\2X\0\1Q\2
00\0\0\0\0\300\f\0\20\0\1\0\0\0\n\0\30\27consul-network-segment=\300\f\0\20\0\1\0\0\0\n\0\34\33tubi_environment=production\300\f\0\20\0\1\0\0\0\n\0\35\34availability_zone=us-west
-2a\300\f\0\20\0\1\0\0\0\n\0\35\34availability_zone=us-west-2b\300\f\0\20\0\1\0\0\0\n\0\34\33tubi_environment=production\300\f\0\20\0\1\0\0\0\n\0\30\27consul-network-segment=\300
\f\0\20\0\1\0\0\0\n\0\35\34availability_zone=us-west-2b\300\f\0\20\0\1\0\0\0\n\0\30\27consul-network-segment=\300\f\0\20\0\1\0\0\0\n\0\34\33tubi_environment=production\300\f\0\20
\0\1\0\0\0\n\0\35\34availability_zone=us-west-2a\300\f\0\20\0\1\0\0\0\n\0\30\27consul-network-segment=\300\f\0\20\0\1\0\0\0\n\0\34\33tubi_environment=production", 4096, 0, {sa_fa
mily=AF_INET, sin_port=htons(8600), sin_addr=inet_addr("127.0.0.1")}, [16]) = 565
Dnsmasq is sending DNS query to Consul and get reply from it.
The whole DNS resolve process is clear now, application query DNS from Dnsmasq, Dnsmasq forward query to Consul, somehow Dnsmasq is not caching DNS response.
Dnsmasq
After looking at Dnsmasq sample config, I can turn on Dnsmasq logging with
log-queries
log-facility=/var/log/dnsmasq.log
The nice thing with log-queries is, from Dnsmasq man page I was able to
Enable a full cache dump on receipt of SIGUSR1
$ tail -f /var/log/dnsmasq.log | grep cache
Nov 27 07:44:04 dnsmasq[22404]: cached 5-26-0-app.agent.datadoghq.com is <CNAME>
Nov 27 07:44:04 dnsmasq[22404]: cached elb-agent.agent.datadoghq.com is 34.226.189.164
Nov 27 07:44:04 dnsmasq[22404]: cached elb-agent.agent.datadoghq.com is 52.22.159.49
Nov 27 07:44:04 dnsmasq[22404]: cached 5-26-0-app.agent.datadoghq.com is <CNAME>
Nov 27 07:44:04 dnsmasq[22404]: cached elb-agent.agent.datadoghq.com is 2600:1f18:63f7:b902:f965:c421:77e5:9835
Nov 27 07:44:04 dnsmasq[22404]: cached elb-agent.agent.datadoghq.com is 2600:1f18:63f7:b900:2b96:26e:a804:4283
$ kill -s SIGUSR1 $DNSMASQ_PID
$ tail -f /var/log/dnsmasq.log
Nov 27 07:49:21 dnsmasq[22404]: time 1543304961
Nov 27 07:49:21 dnsmasq[22404]: cache size 10000, 0/531 cache insertions re-used unexpired cache entries.
Nov 27 07:49:21 dnsmasq[22404]: queries forwarded 3337, queries answered locally 2228
Nov 27 07:49:21 dnsmasq[22404]: queries for authoritative zones 0
Nov 27 07:49:21 dnsmasq[22404]: server 172.40.0.2#53: queries sent 505, retried or failed 0
Nov 27 07:49:21 dnsmasq[22404]: server 127.0.0.1#8600: queries sent 2832, retried or failed 0
Nov 27 07:49:21 dnsmasq[22404]: Host Address Flags Expires
Nov 27 07:49:21 dnsmasq[22404]: ip6-allnodes ff02::1 6FRI H
Nov 27 07:49:21 dnsmasq[22404]: tochigi-2301.herokussl.com elb046917-1045816452.us-east-1.elb.amazo CF Tue Nov 27 07:49:30 2018
Nov 27 07:49:21 dnsmasq[22404]: d39jj1f42o4h8d.cloudfront.net 2600:9000:203a:5600:13:ffa4:f40:93a1 6F Tue Nov 27 07:50:06 2018
Nov 27 07:49:21 dnsmasq[22404]: localhost 127.0.0.1 4FRI H
Nov 27 07:49:21 dnsmasq[22404]: ip6-localnet fe00:: 6FRI H
Nov 27 07:49:21 dnsmasq[22404]: ip6-loopback ::1 6F I H
Nov 27 07:49:21 dnsmasq[22404]: elb-agent.agent.datadoghq.com 52.0.152.181 4F Tue Nov 27 07:49:37 2018
Nov 27 07:49:21 dnsmasq[22404]: elb-agent.agent.datadoghq.com 34.233.117.214 4F Tue Nov 27 07:49:37 2018
Nov 27 07:49:21 dnsmasq[22404]: elb-agent.agent.datadoghq.com 52.87.19.203 4F Tue Nov 27 07:49:37 2018
DNS resolved by AWS is cached, but DNS resolved by consul is not.
Things getting interesting, it’s time to dig into Dnsmasq source code to find out how it decide which DNS response to cache and which not,
/* Don't put stuff from a truncated packet into the cache.
Don't cache replies from non-recursive nameservers, since we may get a
reply containing a CNAME but not its target, even though the target
does exist. */
if (!(header->hb3 & HB3_TC) &&
!(header->hb4 & HB4_CD) &&
(header->hb4 & HB4_RA) &&
!no_cache_dnssec)
cache_end_insert();
Dnsmasq will not cache truncated packet and non-recursive nameservers, what is an truncated packet and why DNS will truncated packet? After google around,
In the absence of EDNS0 (Extension Mechanisms for DNS 0) (see below), the normal behaviour of any DNS server needing to send a UDP response that would exceed the 512-byte limit is for the server to truncate the response so that it fits within that limit and then set the TC flag in the response header. When the client receives such a response, it takes the TC flag as an indication that it should retry over TCP instead.
However we configure Consul with enable_truncate as we need complete service IPs for NGINX and Envoy to do Service Discovery.
Solution
After figure out what cause traffic spike and why DNS cache didn’t work, we are able to fix the problem by introduce Envoy to our frontend service as it already used in our backend services, Envoy act as sidecar proxy will reuse TCP connection instead of create an connection for every request.
Lessons Learned
I was able to learn iftop, tcpdump, strace and dnsmasq, for an network application, tcpdump is useful to see if the traffic go to particular application, while strace is useful to see if an particular application send traffic.
For Dnsmasq, I learned reading logs are useful for debugging, on the other end, I should also think about observability when I write software.