本文简单总结了碎片时间的知识处理体系,目前仅仅是梳理了日常使用中深受其益的部分。
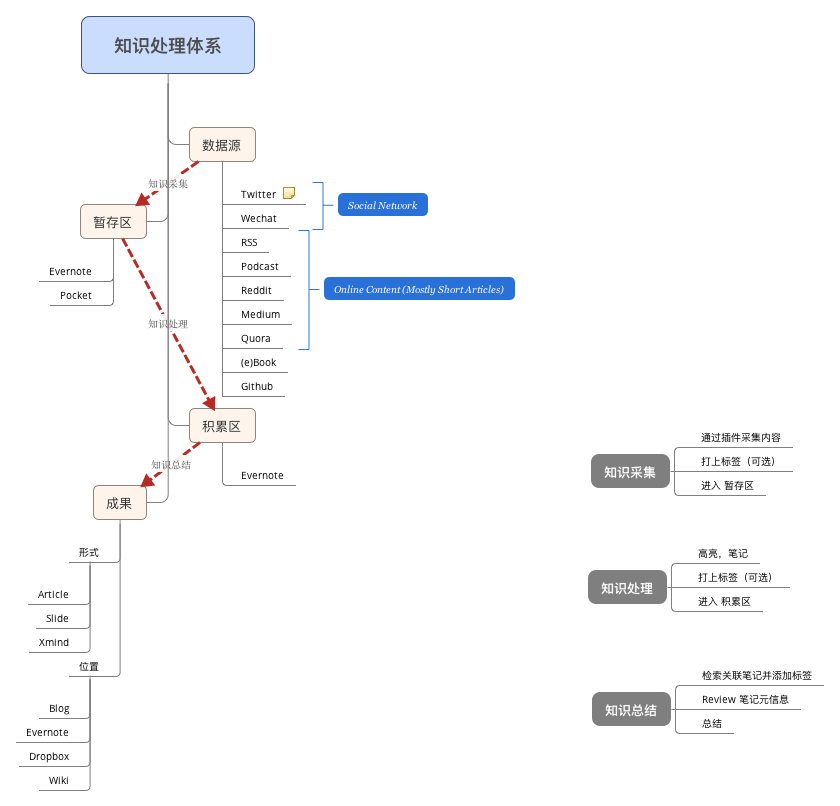
原始数据源通过知识采集,知识处理和知识总结三个步骤,最终转变为个人知识。
工作流
在知识采集程中,为数据源打上标签,并存储在 “暂存区” 笔记本中。
在知识处理过程中,高亮段落,添加笔记,并将笔记转存在 “积累区” 笔记本中。
Tag - 标签
在知识采集,知识处理和知识总结过程中,都会为笔记添加标签。
在知识处理体系中,标签扮演了知识点的角色。
通常在两种情况下会为笔记添加标签
- 在知识采集过程中有明确的目的或兴趣点
- 在知识处理过程中到达某个引爆点(tipping point),发现多个笔记关于同一个内容,这也是一个知识总结的绝佳机会
通常笔记只有一个标签,而标签并不是固定不变的,例如 javascript 标签中的部分笔记在合适的时间会变成 nodejs 标签的笔记。(知识点之间是树状关系,当子知识笔记数量足够多时,应当分割成单独的标签)
标签也为知识总结带来便利,通过生成标签下所有 积累区 内容的链接就是总结中的参考链接;通过解析积累区内容的高亮和笔记还可以抽离出总结的骨架内容。
Notebook - 笔记本
知识处理体系中只有三个笔记本
- 暂存区
- 积累区
- 总结区
其中,总结区仅包含部分总结内容,其余总结内容根据个人需求放在博客或存储与 Dropbox 等地方。
工具
借助标准化的知识处理体系,可以开发出一套通用的处理工具。
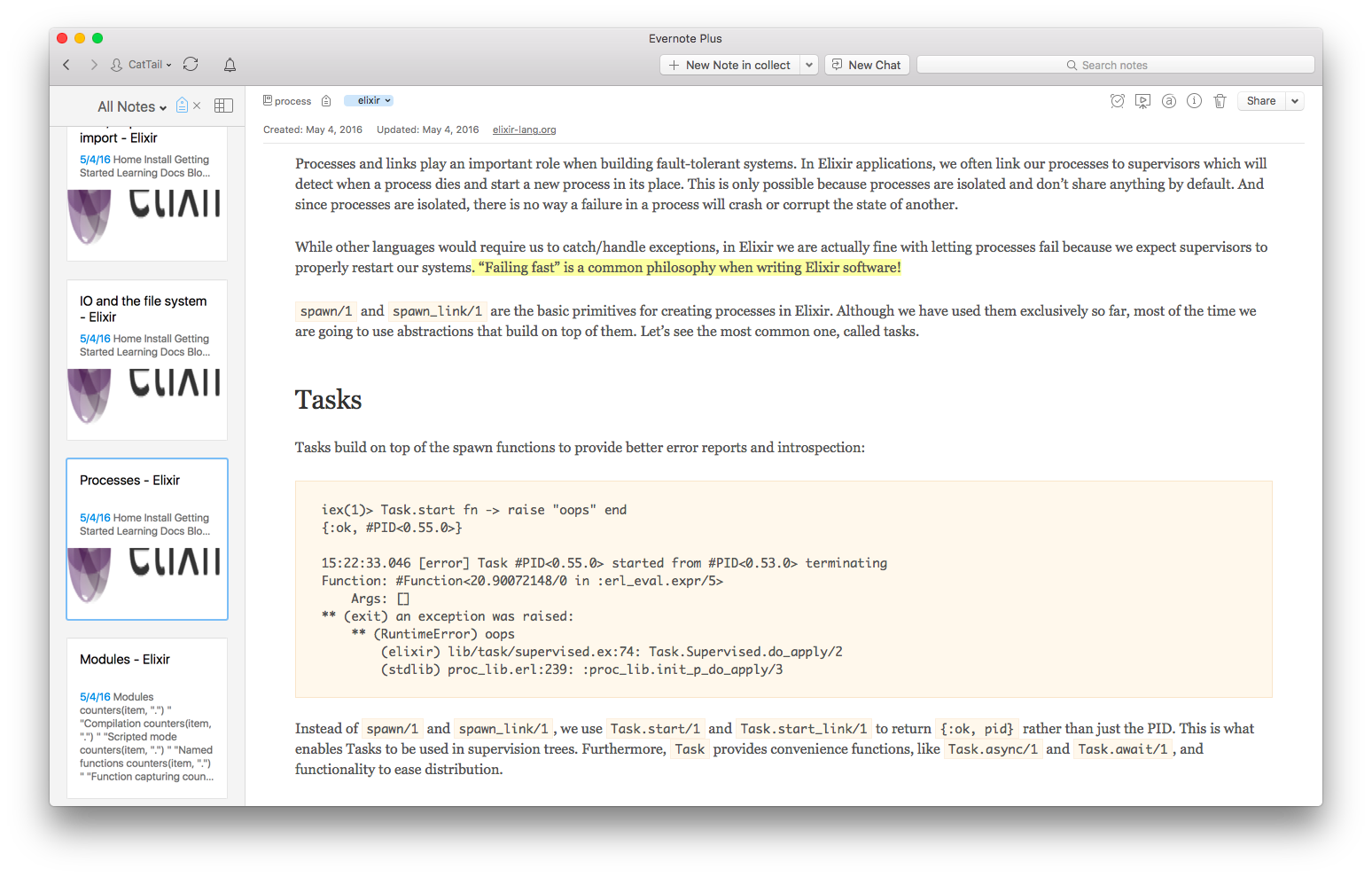
如,对某个知识点 elixir,完成知识处理体系流程后,在 elixir 标签下包含一系列积累区内容和少量的总结区内容
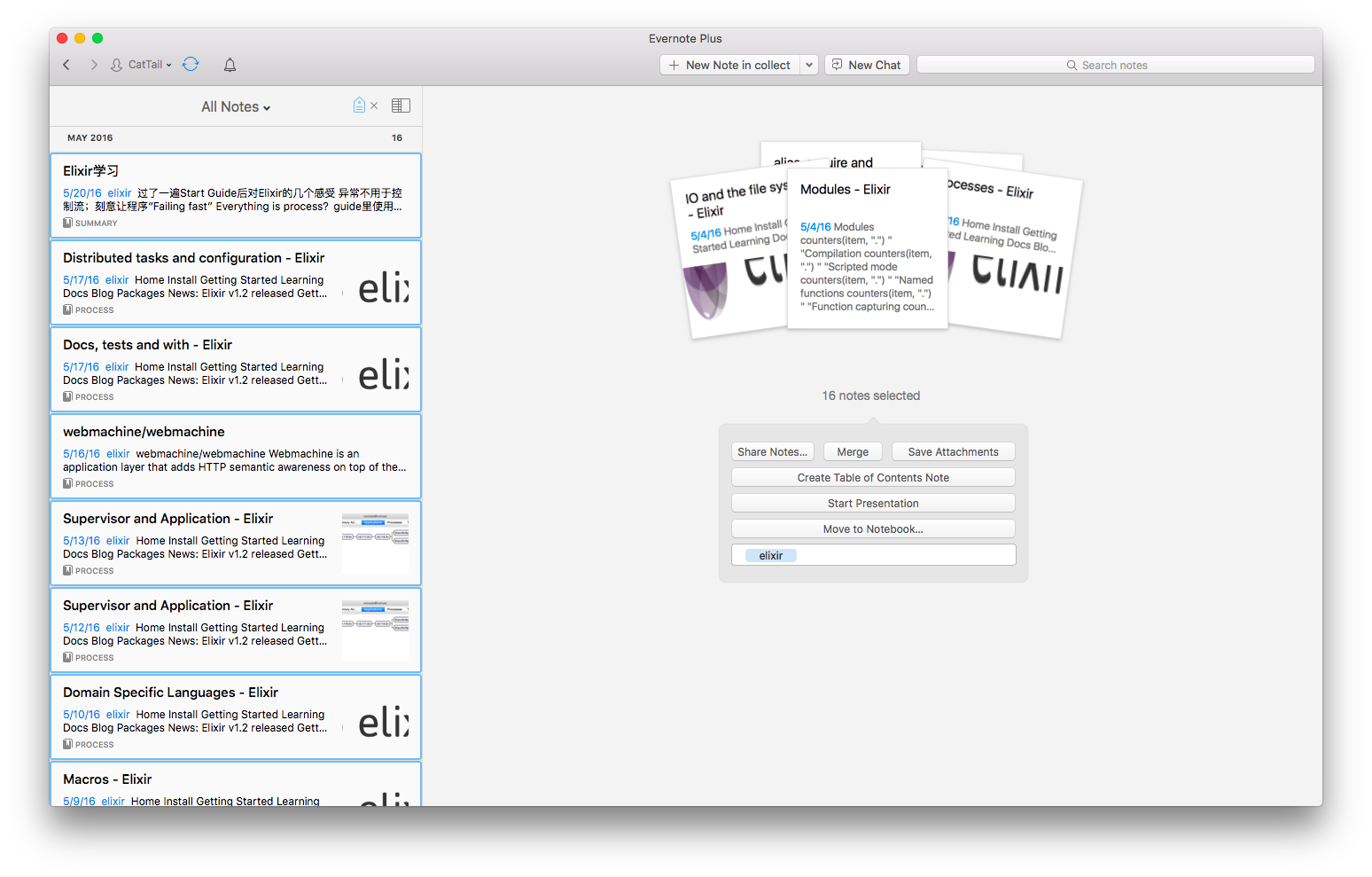
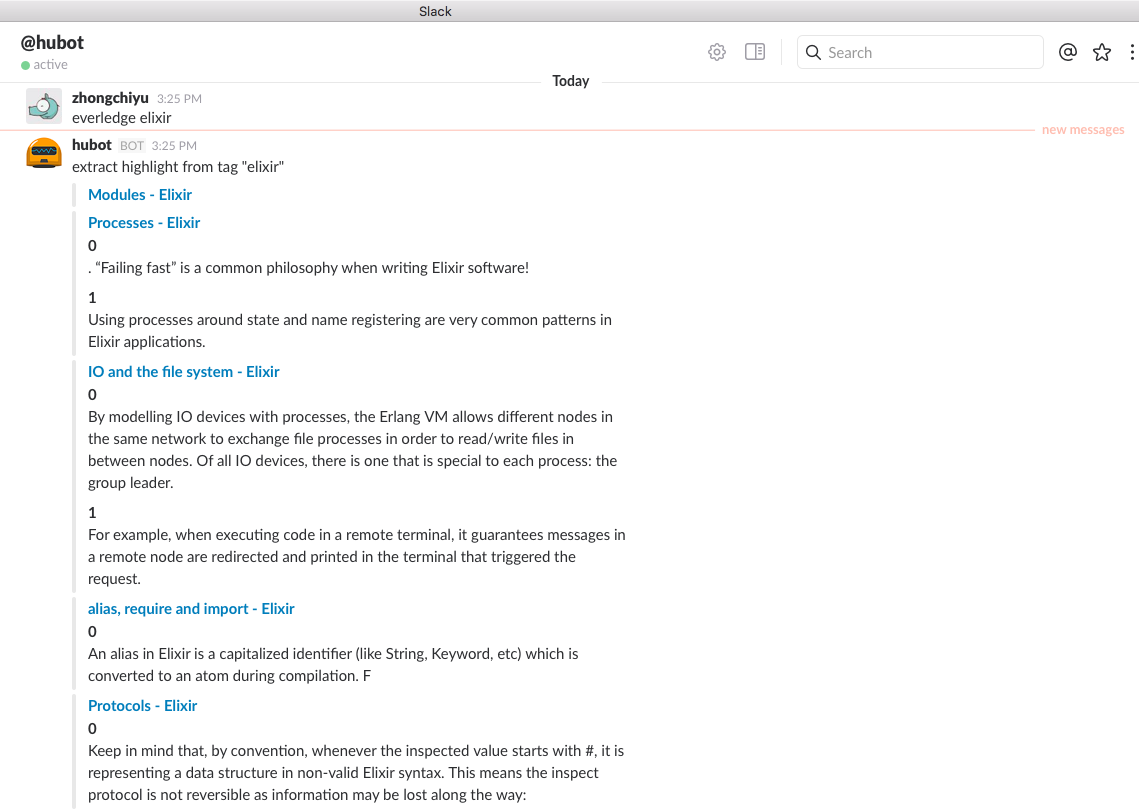
我编写了一个 hubot slack 脚本,用于抽离特定知识点下的所有高亮内容,以便 Review 知识点
其他
优先级
在知识处理体系中如何处理暂存区内容?暂存区存放了所有 Read Later 内容,通常不能被全部清理进入积累区,因而暂存区的定位是这样的
- 存放可能有价值的内容
- 很难也不应该被消化掉,需要使用保证有内容在暂存区中以供碎片时间使用
- 定时清理暂存区中无用信息(移动到 Trash)淘汰机制
- 制定优先级,为高优先级内容增加额外标签 today
进化
知识处理体系的目的是为了提高个人能力,而这体现在体系中的 “成果” 中。
增加成果的一种方式就是“开源” - 使数据源提供数量更多,质量更好的内容。而选择适合自己的数据源并不是一蹴而就的事情,需要不断的修改和校准
-
社交网络:优质的作者通常关联优质的作者
- 参考链接:优质内容通常关联优质内容
- 优质内容作者的其他内容通常质量很高
- 勇于尝试未知的数据源,以免被局限在狭窄领域
- 试用期,信息过多带来的负面,善于unfollow
实例:HTTPS工作原理